ML Ops or MLOps
Set of practices that aims to deploy and maintain machine learning models in production reliably and efficiently.
The word MLOps is a compound of machine learning and the continuous development practice of DevOps in the software field.
- Machine learning models are tested and developed in isolated experimental systems.
- When an algorithm is ready to be launched, MLOps is practiced between Data Scientists, DevOps, and Machine Learning engineers to transition the algorithm to production systems.
- MLOps seeks to increase automation and improve the quality of production models, while also focusing on business and regulatory requirements.


Papers
Salesforce TransmogrifAI
- AutoML library for building modular, reusable, strongly typed machine learning workflows on Apache Spark with minimal hand-tuning
- Transmogrification as the process of transforming, often in a surprising or magical manner, which is what TransmogrifAI does for Salesforce
- enabling data science teams to transform customer data into meaningful, actionable predictions
- thousands of customer-specific machine learning models have been deployed across the platform, powering more than 3 billion predictions every day.
TransmogrifAI is a library built on Scala and SparkML that does precisely this.
With just a few lines of code, a data scientist can automate data cleansing, feature engineering, and model selection to arrive at a performant model from which she can explore and iterate further.
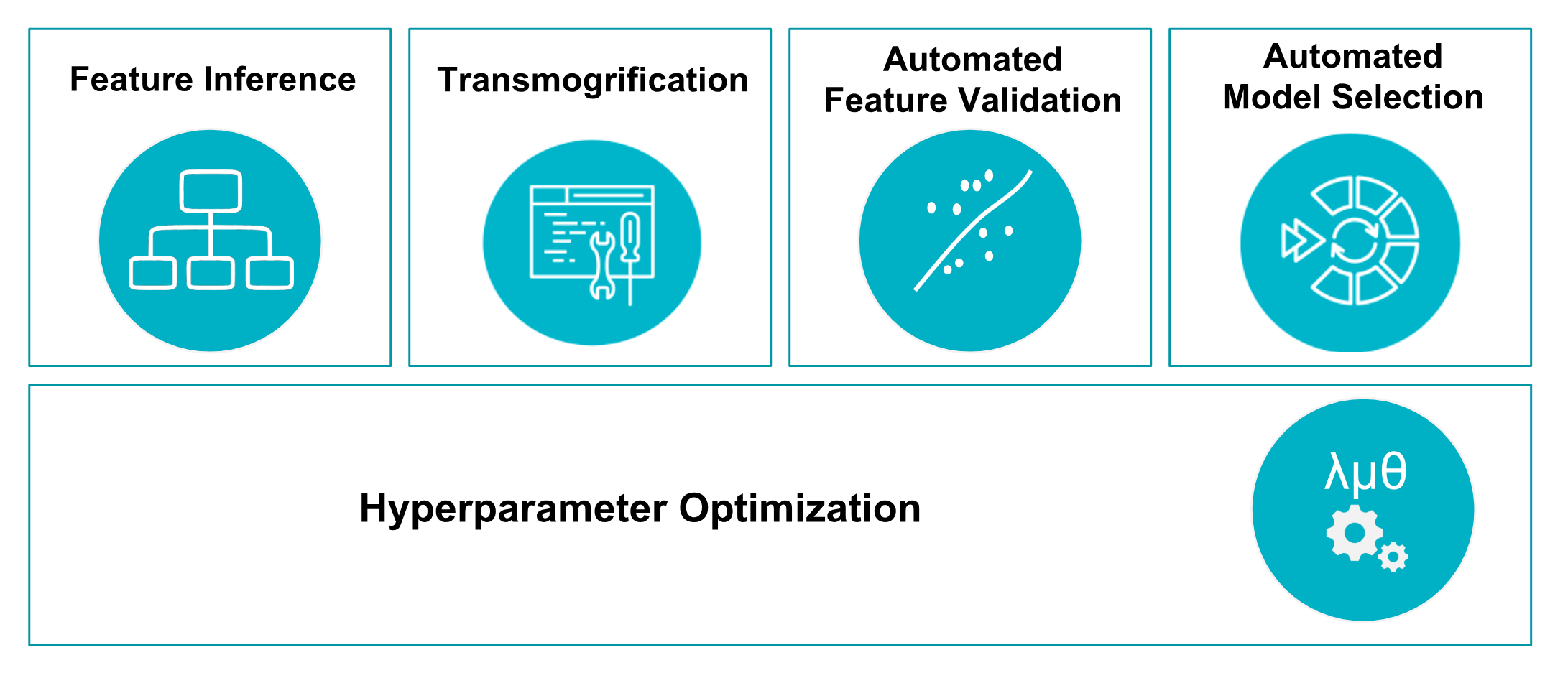
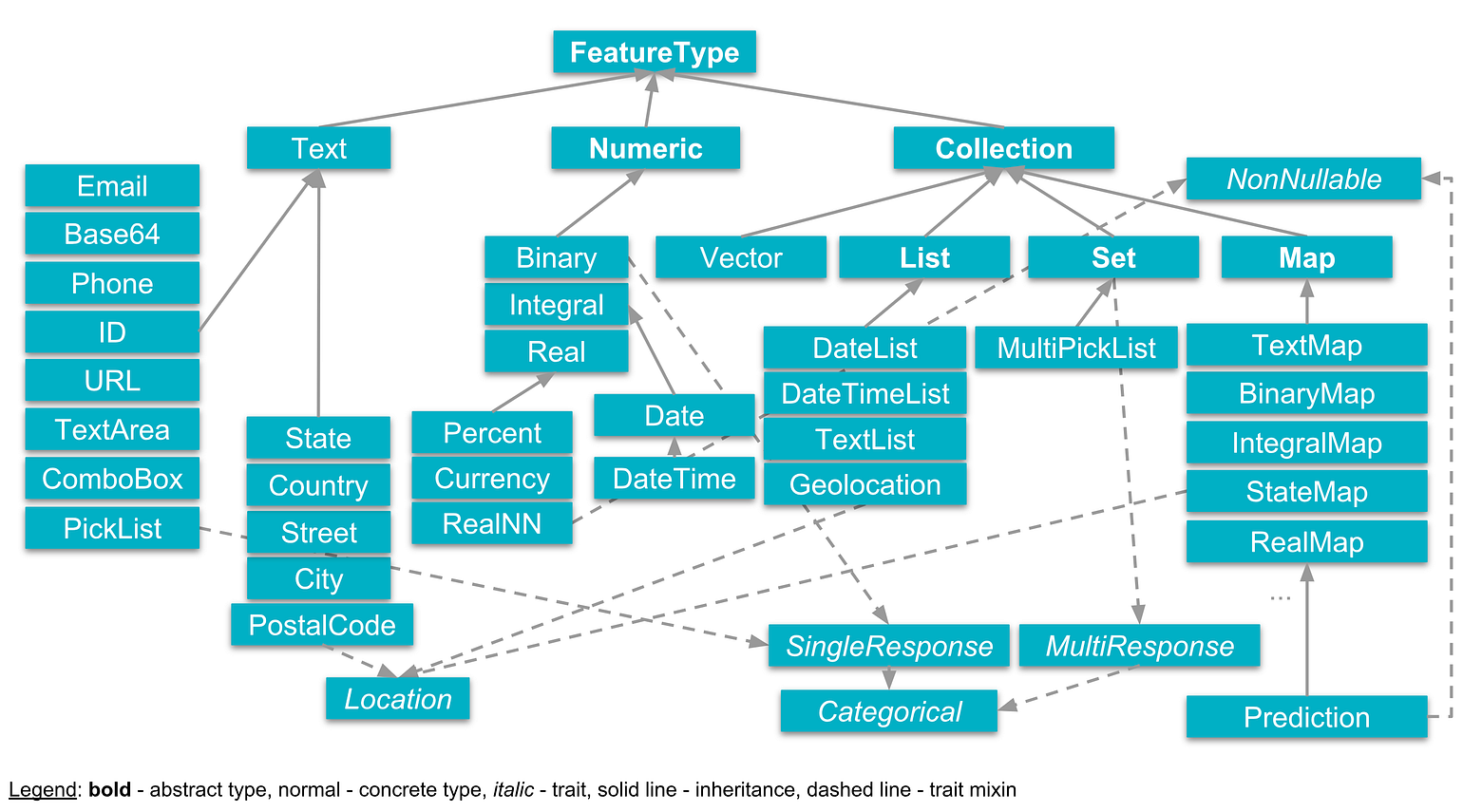
Type Safety: The TransmogrifAI Feature type hierarchy
Transmogrification These transformations are not just about getting the data into a format which algorithms can use, TransmogrifAI also optimizes the transformations to make it easier for machine learning algorithms to learn from the data.
- For example, it might transform a numeric feature like age into the most appropriate age buckets for a particular problem — age buckets for the fashion industry might differ from wealth management age buckets.
TransgmogrifAI has algorithms that perform automatic feature validation to remove features with little to no predictive power. - Example: Closed Deal Amount
The TransmogrifAI Model Selector runs a tournament of several different machine learning algorithms on the data and uses the average validation error to automatically choose the best one
TransmogrifAI comes with some techniques for automatically tuning these hyperparameters and a framework to extend to more advanced tuning techniques.
// Read the Deal data
val dealData = DataReaders.Simple.csvCase[Deal](path = pathToData).readDataset().toDF()
// Extract response and predictor Features
val (isClosed, predictors) = FeatureBuilder.fromDataFrame[RealNN](dealData, response = "isClosed")
// Automated feature engineering
val featureVector = predictors.transmogrify()
// Automated feature validation
val cleanFeatures = isClosed.sanityCheck(featureVector, removeBadFeatures = true)
// Automated model selection
val (pred, raw, prob) = BinaryClassificationModelSelector().setInput(isClosed, cleanFeatures).getOutput()
// Setting up the workflow and training the model
val model = new OpWorkflow().setInputDataset(dealData).setResultFeatures(pred).train()
TransmogrifAI is built on top of Apache Spark
-
Able to handle large variation in the size of the data
- Some use cases involve tens of millions of records that need to be aggregated or joined, others depend on a few thousands of records.
-
Spark has primitives for dealing with distributed joins and aggregates on big data
-
Able to serve our machine learning models in both a batch and streaming (Spark Streaming) setting
-
Transmogrification, Feature Validation, and Model Selection above, are all powered by Estimators)
- A Feature is essentially a type-safe pointer to a column in a DataFrame and contains all the information about that column — its name, the type of data it contains, as well as lineage information about how it was derived.
-
TransmogrifAI provides the ability to easily define features that are the result of complex time-series aggregates and joins
-
Features are strongly typed. This allows TransmogrifAI to do type checks on the entire machine learning workflow, and ensure that errors are caught as early on as possible instead of hours into a running pipeline
-
Developers can easily specify custom transformers and estimators to be used in the pipeline
val lowerCaseText = textFeature.map[Text](_.value.map(_.toLowerCase).toText)
Scale and performance
- With automated feature engineering, data scientists can easily blow up the feature space, and end up with wide DataFrames that are hard for Spark to deal with.
- TransmogrifAI workflows address this by inferring the entire DAG of transformations that are needed to materialize features, and optimize the execution of this DAG by collapsing all transformations that occur at the same level of the DAG into a single operation.
Summary
TransmogrifAI enables our data scientists to deploy thousands of models in production with minimal hand tuning and reducing the average turn-around time for training a performant model from weeks to just a couple of hours.