TPU - Tensor Processing Units
TPUs are Google’s custom-developed application-specific integrated circuits (ASICs) used to accelerate machine learning workloads.
Designed from the ground up with the benefit of Google’s deep experience and leadership in machine learning.
Enable us to run our machine learning workloads on Google’s TPU accelerator hardware using TensorFlow
Designed for maximum performance and flexibility to help researchers, developers, and businesses to build TensorFlow compute clusters that can leverage CPUs, GPUs, and TPUs.
High-level TensorFlow APIs help us to get models running on the Cloud TPU hardware.
Advantages for using TPUs
-
Cloud TPU resources accelerate the performance of linear algebra computation, which is used heavily in machine learning applications.
-
TPUs minimize the time-to-accuracy when you train large, complex neural network models. Weeks to hours (150 times faster)
- Models that previously took weeks to train on other hardware platforms can converge in hours on TPUs.
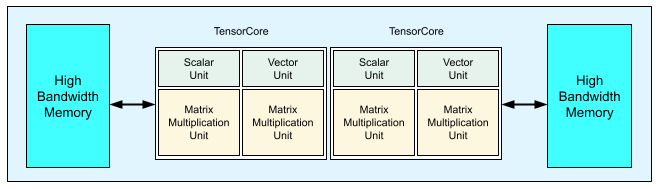
TPU v3
A TPU v3 board contains four TPU chips and 32 GiB of HBM. Each TPU chip contains two cores. Each core has a MXU, a vector unit, and a scalar unit.