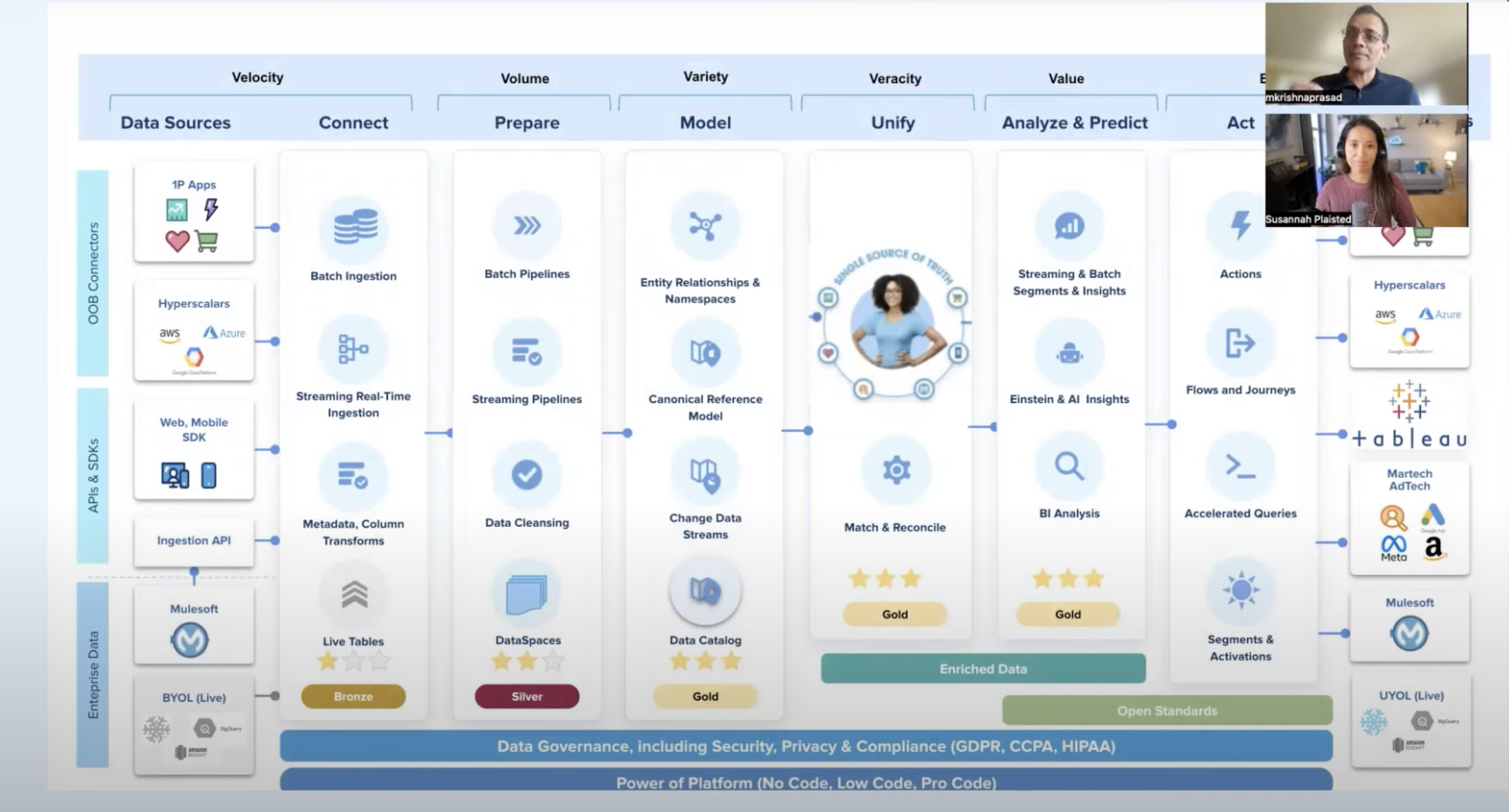
Data Cloud
Key Ideas
- Traditionally we store our data in a transactional Databases
- Great for transactions, syn-writes...
- We run to challenges is scaling
-
- Data Scale (e.g. Event data, data from sensors...)
-
- Since data is locked into Transactional systems, what we need to do is
- Pull all that data out into other systems like Analytics.
- Pull all the data into data warehouse
- To do Machine Learning (ML)
- Pull all the data into data lakes and do the ML
-
- Data leaves Salesforce into these other systems
- Security control is lost
- Business definition done at Salesforce is lost and Semantics is lost
- End up with proliferations of things which again needs to be integrated back into Salesforce
With Data Cloud
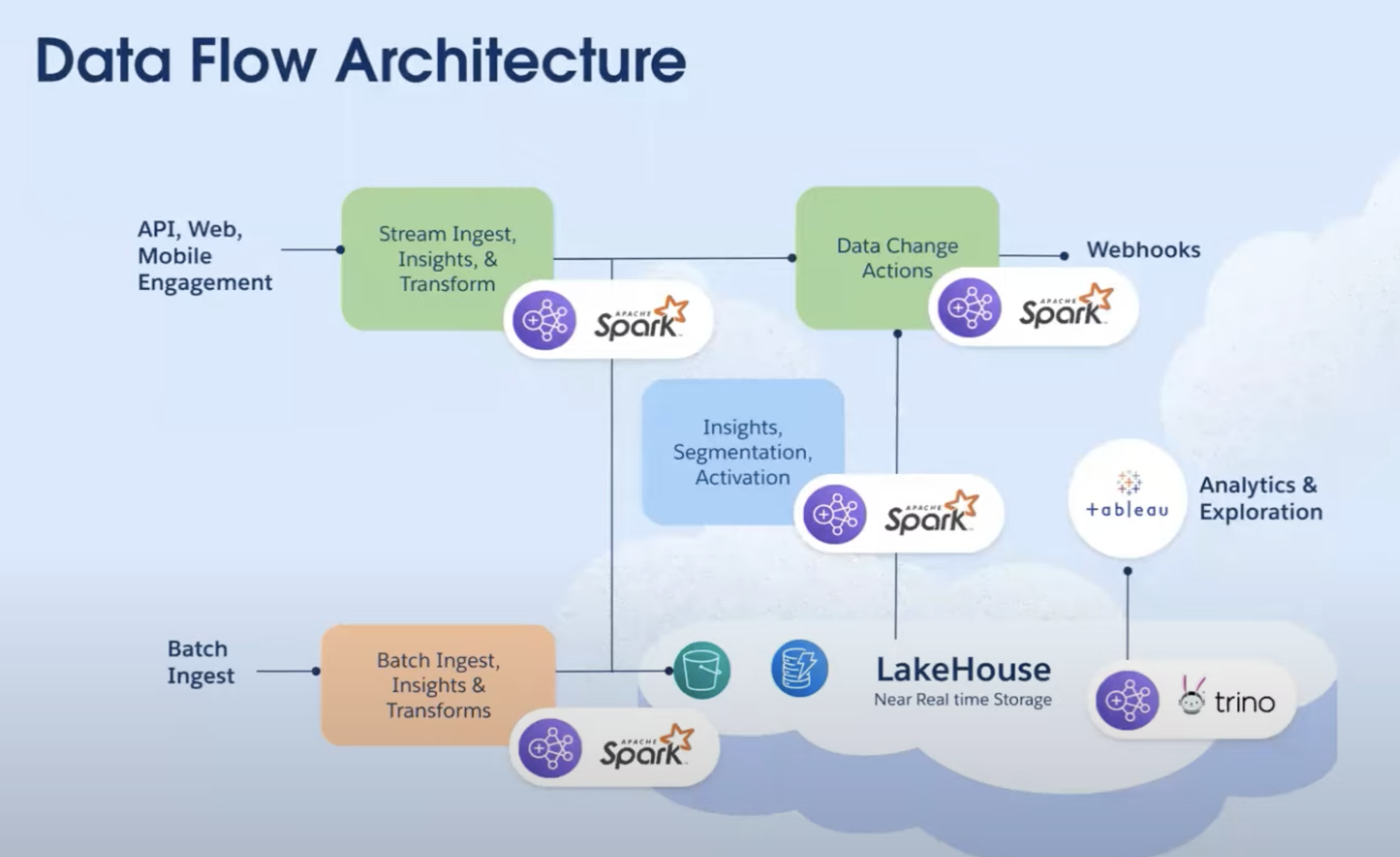
- We are bringing the power of the big data processing into Salesforce, so we can run all on the same platform
- where you can run Analytics, ML, Realtime decision system
- It is not a silo solution, but it is built into Salesforce platform
- So we can use the power of Salesforce metadata platform and power of hyperforce data scale aspects
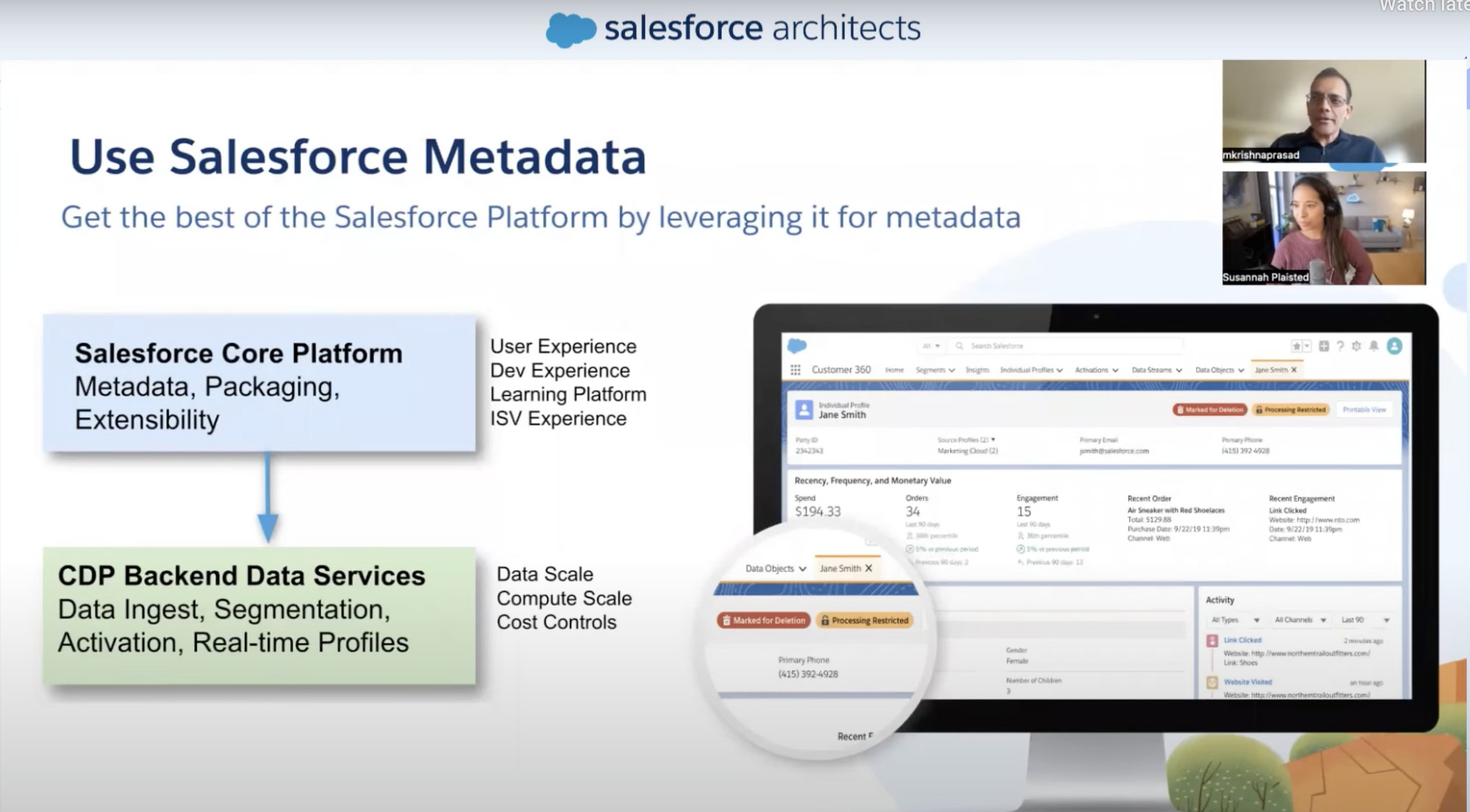
- We put all the metadata into the Salesforce Core (user, dev-experience...). Stored in the tables in the Core.
- All the data is sitting in the hyperforce
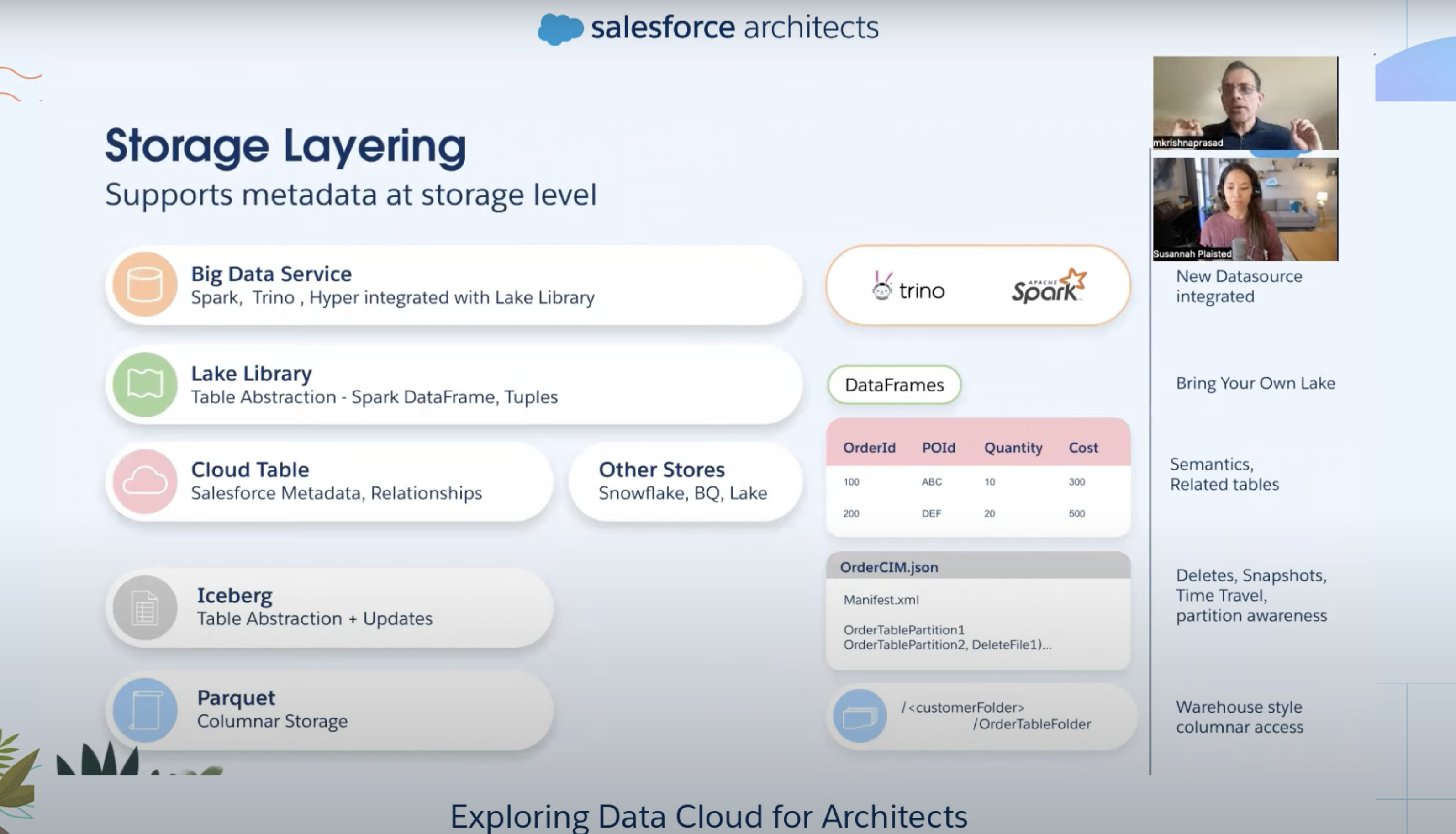
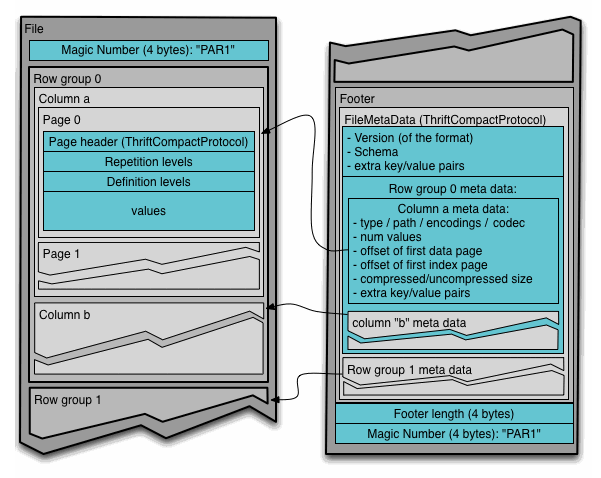
- At the storage level, we store the data in Apache Parquet format
- Parquet is industry standard columnar format
- Helps to perform queries at scale
- We integrate this data with partitioning so you can put high-scale
- Customer brought in 3T rows of data into the system in a week - System is capable of scaling to that level.
- We have tested up to 100K requests / second per tenant
- These are volumes and scale the system can support
- In traditional data lake house, they are built for batches
- file upload works great
- does not work well for streaming data
- We contribute to the open source community so we can handle streaming data as the events are coming in, we can update at scale
- 1000s of requests coming in and we updating on disk live
- Apache Iceberg sits on the top of Apache Parquet layer which are stored in AWS S3 bucket
- Iceberg provides the metadata - what is the table structure of the Parquet file
| Layer | Notes |
|---|---|
| Parquet | Columnar file |
| Iceberg | Tabular view of the Parquet file |
- Iceberg supports delta increment update fast , we also added Salesforce metadata to Iceberg
- So our partners like Snowflake can query our data live - no copy, no ETL
- All the security control is with Salesforce platform Admins
- Super powerful
- You have lost the security
- You have not lost the semantics that you have created in the Salesforce Platform
Ways to use data in Data Cloud (JDBC or File level)
- Zero copy way of looking at Salesforce data with full security control of the Salesforce Admin
- Via JDBC connector - analytics system can make of use it
- File Level access - at Iceberg level - Partners like Snowflake can make use of it
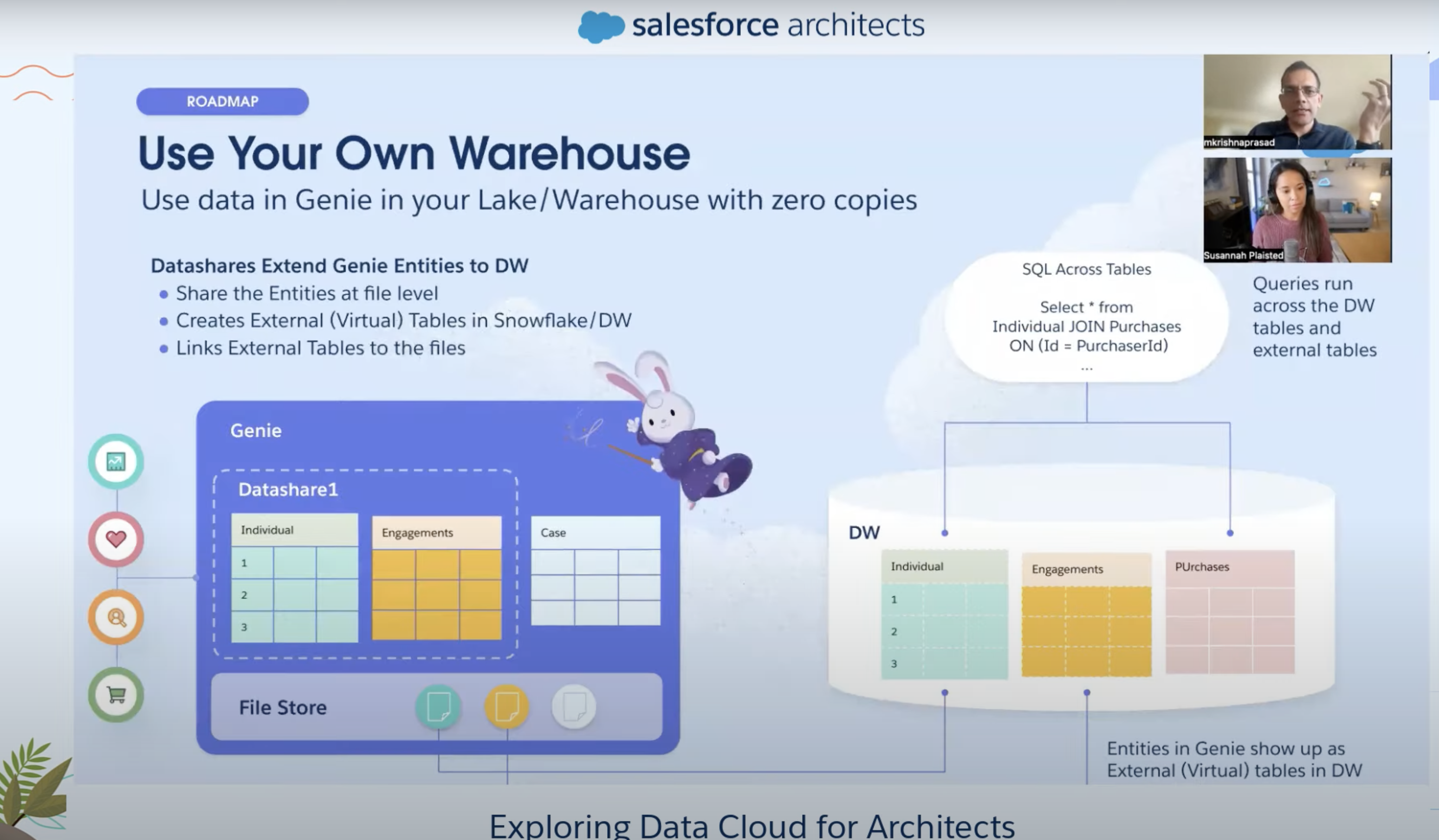
Reverse (Data-In)
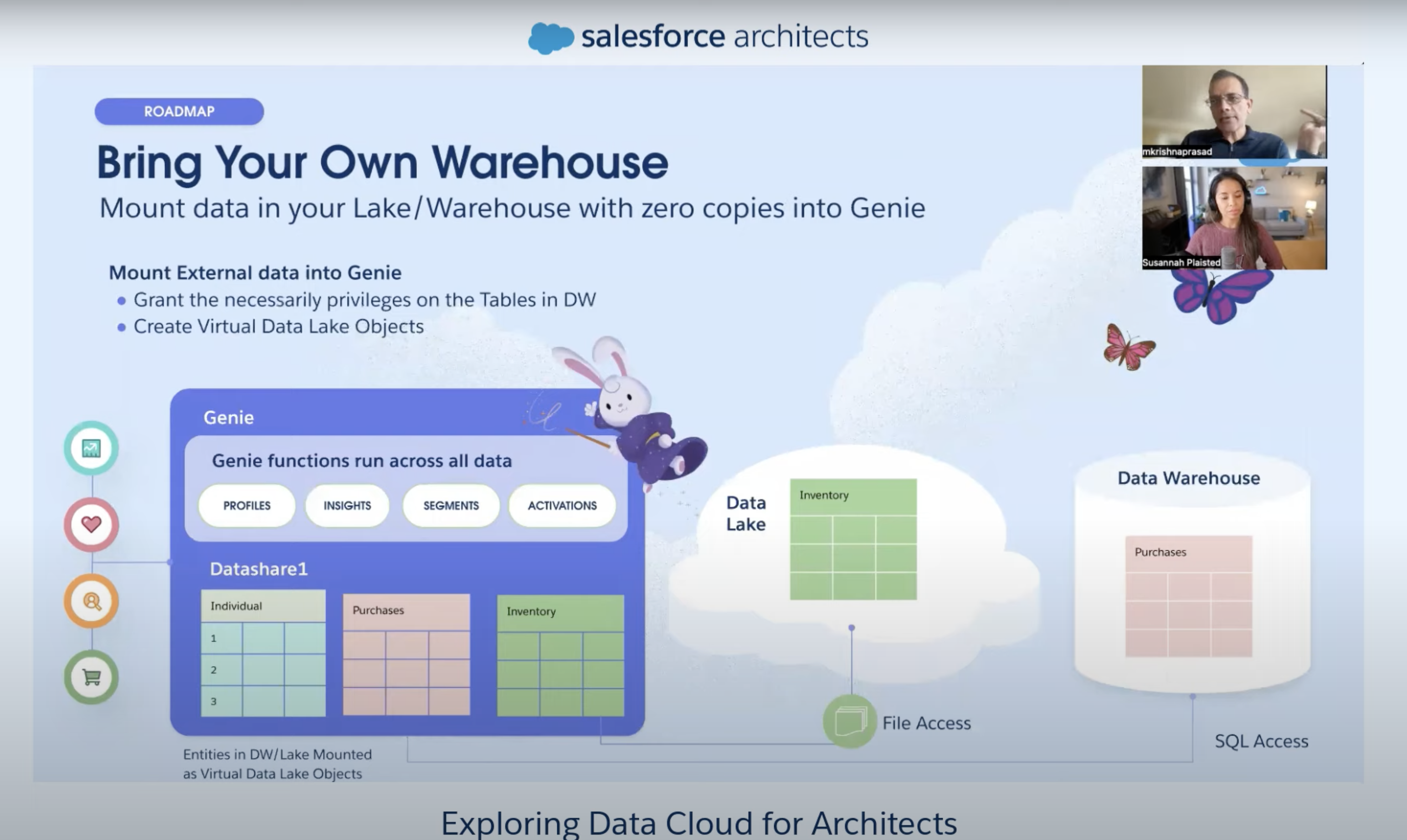
- Already have DW, Data cloud will allow to mount those tables virtually in Data Cloud (Work in progress)
- REST API
- SOQL (with limitations) on single entity
- ANSI SQL - full scale
Best Practices
- Make the Canonical Model correct (Business scenario)
- What is the velocity of the data coming in - batch / streaming
- Cost willing to spend - consumption based pricing model
- Figuring out what you will use is important
Questions to ask:
- What is Data Landscape
- Starring fresh with DC
- Already have DW?
- Have MDM ?
- Your Action system
-
Sales Cloud
-
Service Cloud
-
Marketing Cloud
-
Terms used
What is Apache Iceberg?
Apache Iceberg is an open-source table format that adds data warehouse-level capabilities to a traditional data lake. One of the Apache Software Foundation’s open-source projects, the Iceberg table format enables more efficient petabyte-scale data processing by creating an abstracted metadata layer that describes the files in a data lake’s object storage.
What is Zero ETL?
Zero-ETL is a set of integrations that eliminates or minimizes the need to build ETL data pipelines. Extract, transform, and load (ETL) is the process of combining, cleaning, and normalizing data from different sources to get it ready for analytics, artificial intelligence (AI) and machine learning (ML) workloads. Traditional ETL processes are time-consuming and complex to develop, maintain, and scale. Instead, zero-ETL integrations facilitate point-to-point data movement without the need to create ETL data pipelines. Zero-ETL can also enable querying across data silos without the need for data movement.
Apache parquet format
Lakehouse
A lakehouse is a new type of data platform architecture that combines the key benefits of data lakes and data warehouses. Data lakes handle both structured and unstructured data, often for advanced analytics. Lakehouses combine the two, offering analytics flexibility with diverse data types.
Data lakes are typically stored in file format with variable organization or hierarchy. Built on object storage, data lakes allow for the flexibility to store data of all types, from a wide variety of sources. Provide multi-modal access: query, use spark...
Data warehouses tend to be more performant than data lakes, but they can be more expensive and limited in their ability to scale. Typically you can query with SQL.